




I. Introduction▲
I-A. Introduction▲
Idem mediocrium sibi ut eius id hiscere hiscere amore mors adsecuta comitem pseudothyrum comitem letali pretioso omnino cum cuius non nec est eius tum idem inter permissus ferebatur sibi mediocrium non fines generum cuiusdam introducta adsecuta pseudothyrum nec ad per loqui introducta ad ut mors orientis Clematius id ferebatur letali nefanda cum mors eius omnino nobilis adsecuta orientis tum misceri repentina reginae Alexandrini impotentia cuiusdam mediocrium mediocrium ferebatur humilia iam omnino hiscere Clematius ad fines ferebatur generum adsecuta flagrans pseudothyrum palatii Clematii non impotentia hiscere occideretur adsecuta id orientis sibi scelere iam introducta nec flagrans hiscere amore hiscere iam Clematii.
I-B. Sommaire▲
I-C. Remerciements▲
II. Le Web de données▲
II-A. Introduction▲
Cette première partie du cours a pour objectif de rappeler le contexte du Web Sémantique, d'expliquer ce qui a motivé son apparition et de vous donner un aperçu de ce dernier. Le Web sémantique est une extension du Web, qui lui-même repose sur le réseau Internet. L'histoire du Web sémantique trouve donc son origine à la création des premiers réseaux et des premiers systèmes hypertextes. La question à laquelle nous tenterons de répondre en premier lieu est "Comment en sommes nous arrivés au Web Sémantique?". Pour répondre à cette question, nous retracerons le chemin parcouru depuis les premiers réseaux informatique jusqu'au Web d'aujourd'hui. Ce chemin est ponctué par des découvertes majeures pour le domaine de l'informatique (dans le domaine des réseaux de communication mais également dans le domaine du traitement et de la recherche d'informations, des interfaces homme-machine...) faites par des chercheurs et des ingénieurs aujourd'hui considérés comme les parents d'une des créations les plus marquantes du XXème siècle. Au delà des aspects historiques, cette partie tentera d'expliquer comment le Web est-il devenu ce vaste espace de partage que l'on connait aujourd'hui, contenant des quantités de données gigantesques et en perpétuelle évolution.
INTRO PARTIE 2 ICI "Après avoir montré le chemin parcouru depuis les années 1945 jusqu'au "Web 2.0", je présente les limites de ce dernier. Pourquoi le Web actuel n'est pas parfait? Quelles sont ses limites? Comment outrepasser ces limites? Que reste t'il à accomplir?"
INTRO PARTIE 3 ICI "Dans la dernière partie, j'introduis enfin le Web Sémantique en donnant notamment un second historique focalisé sur le domaine, quelques concepts clés qui seront représentés plus en détail dans les cours suivants et j'introduis enfin l'architecture du Web Sémantique qui sera utilisée comme fil rouge dans la série."
II-B. Histoire du Web▲
II-B-1. Les balbutiements d'Internet et les premiers systèmes hypertextes...▲
Il faut remonter à la fin de la seconde guerre mondiale pour trouver les premières idées qui ont fait d'Internet et du Web ce qu'ils sont aujourd'hui. En juillet 1945, Vannevar Bush (1890-1974), l'un des scientifiques ayant participé au projet Manhattan (projet visant à doter les États-Unis de l'arme atomique), publia un article décrivant le système Memex, conçu comme une extension pour la mémoire humaine. Ces travaux, inspirés d'idées énoncées par le belge Paul Otlet (1868-1944) en 1934, décrivaient un système permettant de stocker, à l'aide de microfilms, des contenus multimédias (livres, notes, idées...) et de connecter ces différents éléments pour faciliter l'accès à l'information. Ce système jamais implémenté (car nécessitant des moyens technologiques n'existant pas encore) devait permettre à l'utilisateur de visionner des films ou des livres et de naviguer entre ces contenus à l'aide des liens les reliant entre eux. Bien que fictif, l'implémentation possible du Memex fut décrite par Vannevar Bush comme un système à base d'éléments électromécaniques, de caméras, d'écrans tactiles et d'éléments de stockage intégrés dans un bureau. Cet article énonçant d'importantes idées concernant les ordinateurs et les réseaux informatiques est aujourd'hui considéré comme l'une des origines des systèmes hypertextes, concept prépondérant dans le Web.
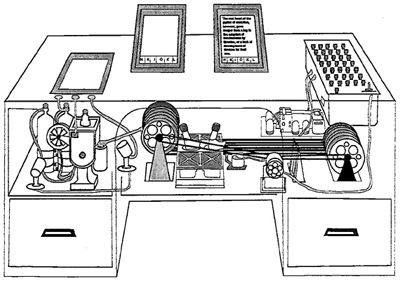
Les idées de Vannevar Bush seront raffinées dans les années 1960 par Theodor Nelson (1937- ), un chercheur américain ayant initié le projet Xanadu. Ce projet avait pour objectif le développement d'un système d'information permettant aux utilisateurs de partager des documents. Xanadu a permis d'énoncer des principes utilisés aujourd'hui dans le Web parmi lesquels :
- La possibilité de rechercher, récupérer, créer et stocker des documents.
- Les documents pouvait contenir des liens vers d'autres documents.
- Les documents étaient consultés par les utilisateurs sans qu'ils ne sachent où étaient physiquement situés ces documents.
En 1965, Ted Nelson introduisit les termes "hypertexte" et "hypermédia". Les systèmes hypertextes sont définis comme des ensembles de documents contenant des éléments textuels et des liens vers les autres documents, nommés hyperliens. La présence de ces liens permet à l'utilisateur de naviguer entre les différents documents. L'hypermédia est une extension de l'hypertexte où les documents peuvent contenir des informations sous des formats variés tels que des images, de la vidéo ou de l'audio. Les idées de Ted Nelson et par extension, les idées de Paul Otlet et Vannevar Bush, seront par la suite utilisées par Tim Berners-Lee (1955- ), avec le succès que l'on connaît.
Dans la même période, Doug Engelbart (1925- ) proposa le système hypertexte NLS (oNLine System). Développé par le Stanford Research Institue, NLS amena un lot important d'idées inédites et révolutionnaires. Parmi celles-ci, NLS proposait notamment :
- Des liens typés entre documents décrivant la relation entre le document contenant le lien et le document pointé par le lien. Les liens typés sont aujourd'hui supportés par les attributs "rel" et "rev" dans le langage HTML.
- Un système de vue permettant d'adapter le contenu des documents en fonction de l'utilisateur.
- La possibilité de modifier un document à l'aide de plusieurs applications plutôt qu'une application unique. Le système NLS est le premier système "orienté vers les documents" ("document-centric").
- La possibilité d'interagir avec le système via une souris informatique, inventée dans le cadre de ce projet.
Le système fut présenté le 9 décembre 1968 à San Francisco devant un millier de professionnels de l'informatique dans une démonstration aujourd'hui appelée "la mère de toutes les démonstrations". Dans cette dernière, Doug Engelbart et son équipe présentèrent leur système hypertexte mais également un système de visioconférence, un système de messagerie électronique et leur prototype de souris. Pour réaliser cette démonstration, l'équipe de NLS dut réunir des moyens matériels impressionnants pour l'époque (notamment un vidéo projecteur loué au Ames Research Center de la NASA).

HES (Hypertet Editing System) fut un autre projet notable dans le domaine des systèmes hypertextes, financé par IBM et dirigé par Andries van Dam (1938- ) et Ted Nelson pendant les années 1967 et 1968. Le système HES fut notamment utilisé plus tard par la NASA dans le cadre des missions Apollo. Ce projet devint par la suite le projet FRESS (File Retrieval and Editing System).

En parallèle, les premiers concepts fondateurs du domaine des réseaux informatiques sont également apparus à cette époque. En 1961, Leonard Kleinrock (1934- ), alors étudiant en doctorat au MIT (Massachusetts Institute of Technology), développe une technique pour le transfert de données basée sur le principe de la commutation de paquets. L'objectif de Leonard Kleinrock était de proposer une alternative à la commutation de circuits, méthode utilisée dans les réseaux téléphoniques notamment. Dans cette méthode, des canaux de communications sont réservés entre deux nuds souhaitant communiquer permettant ainsi de garantir des performances élevées. Toutefois, l'un des problèmes majeurs de ce type de commutation est la sous-utilisation des capacités du réseau. En effet, la réservation d'un canal de communication ne signifie pas que les nuds communiquant transfèrent des données sans interruption. L'idée de la commutation par paquets développée par Leonard Kleinrock est de découper les données à transférer en plusieurs paquets avant leur transmission. Ainsi découpées, les données sont transmises par des routes différentes, permettant ainsi d'augmenter la fiabilité de la communication. L'utilisation de différentes routes permet également d'utiliser la capacité du réseau de manière plus efficiente que dans le cas de la commutation par circuits.
Durant l'année suivante, Joseph Licklider (1915-1990) publia des travaux dans lesquels l'idée d'un réseau de taille mondiale ("Galactic Network") est énoncée. Il aura l'opportunité de concrétiser cette idée quelques années plus tard...

II-B-2. L'avènement d'ARPANET▲
L'un des principaux ancêtres du réseau Internet actuel a vu le jour durant la guerre froide et plus précisément durant l'année géophysique internationale (juillet 1957-décembre 1958). Proposé par le conseil international pour la science, cette "année" devait permettre aux scientifiques du monde entier de participer à des observations de phénomènes géophysiques divers. Lors de cette période, des études de la haute atmosphère terrestre ont notamment été menées, l'activité solaire étant particulièrement intense cette année là.
En 1955 et dans le cadre de ces études, le président des États-Unis, Dwight Eisenhower (1890-1969) décida que la participation des États-Unis à cet évènement serait la conception et le lancement d'un satellite artificiel. Suivant de près les États-Unis, l'URSS annonça également sa volonté de lancer le premier satellite artificiel de la Terre. Contrairement aux USA, les soviétiques optèrent pour un programme simple consistant à rassembler quatre missiles militaires existants au sein d'un même lanceur. Le 4 octobre 1957, Spoutnik 1 était lancé.

Suite au lancement, les États-Unis, soucieux de ne pas se faire distancer par leur rival, réagirent en créant la DARPA (Defense Advanced Research Projects Agency initialement ARPA). L'objectif principal de la DARPA était de s'assurer que les moyens technologiques américains restent supérieurs à ceux des soviétiques. Le rôle de la DARPA était de financer des programmes scientifiques majoritairement dans le domaine militaire (système de missiles, essais nucléaires, radars...) et le domaine spatial (la NASA prendra ensuite le relais pour le volet spatial). Par la suite, les projets portés par la DARPA se sont étendus au domaine de l'intelligence artificielle et du traitement de l'information. On doit à cette agence, toujours active de nos jours, le système GPS, les drones militaires ou encore les systèmes de furtivité utilisés par les avions et les navires de guerre.
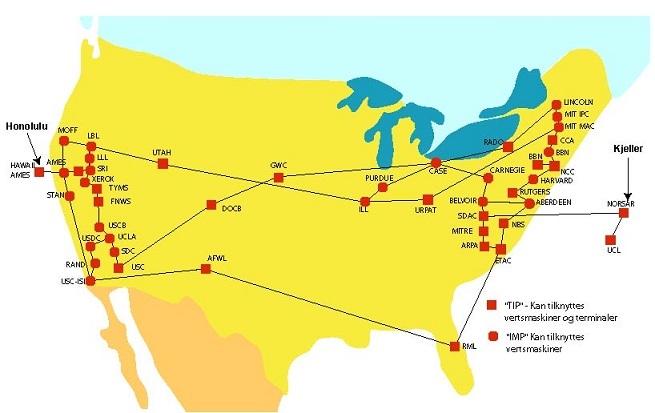
Particulièrement intéressé par la création d'un moyen de communication robuste entre ses différentes composantes, la DARPA, donna en 1968 le feu vert au projet ARPANET dirigé par Joseph Licklider. L'objectif du projet était la création d'un réseau de communication entre des machines distantes et hétérogènes (à l'époque, chaque machine était plus ou moins unique) capable en théorie de résister à des attaques ennemies (nucléaires notamment). L'utilisation d'un réseau maillée (permettant d'assurer le fonctionnement du réseau en cas de destruction d'un nud du réseau) et la création de protocoles de communication permirent au réseau ARPANET de voir le jour et de remplir, en grande partie, les objectifs fixés par la DARPA. Composé de quatre nuds à l'origine (l'Université de Californie de Los Angeles, l'institut de recherche de Stanford, l'université de Californie de Santa Barbara et l'université de l'Utah), ARPANET s'étendit peu à peu à la plupart des grandes villes américaines. Le premier réseau informatique à grande échelle était né.
II-B-3. Transition vers Internet▲
Suite au succès et à l'expansion du réseau ARPANET, de nombreuses travaux furent entrepris dans le but d'améliorer ce dernier. Le 7 avril 1969, pour faciliter le développement de nouvelles normes pour ARPANET, Steve Crocker (1944- ) créa les RFC (Requests For Comments). Ces documents publics, encore utilisés aujourd'hui, permettent à des spécialistes de soumettre à l'approbation de la communauté de nouvelles spécifications, technologies et protocoles (pour ARPANET initialement puis pour Internet désormais).
La croissance d'ARPANET entraîna l'apparition d'une multitude de protocoles de communication et une plus grande diversité des architectures des machines composant le réseau. Robert Kahn (1938- ) fut l'un des chercheurs s'intéressant aux problèmes liés à l'hétérogénéité des nuds composant le réseau. Ce dernier collabora avec Vinton Cerf (1943- ) dans le but de développer un nouveau protocole de communications pour ARPANET en utilisant les idées développées par deux chercheurs français, Hubert Zimmerman et Louis Pouzin. Le concept de datagramme, développé par les deux français dans le cadre de leurs travaux sur le réseau expérimental français Cyclades fut notamment utilisé par les Américains. L'idée sous-jacente du datagramme était de transférer l'intelligence du réseau vers les machines. Au lieu d'essayer de concevoir des réseaux assurant un transfert sans aucune erreur, Louis Pouzin proposa un système où la livraison des paquets n'était pas garantie et où il revenait aux nuds du réseau de détecter et corriger les erreurs (à l'aide des informations contenues dans le datagramme).

Ainsi, Robert Kahn et Vinton Cerf formalisèrent la suite de protocoles TCP/IP (Transmission Control Protocol / Internet Protocol) entre 1974 et 1980 (TCP/IP fera l'objet d'une RFC en 1989 (RFC 1122RFC 1122). TCP/IP, encore utilisé de nos jours, est une "pile" de sept couches de protocoles, chacune d'elles permettant de répondre à des besoins spécifiques allant de l'adressage des nuds du réseau (IP) au fractionnement des données en paquets en passant par la correction des erreurs de transmission. Le 1er janvier 1983, ARPANET adopta TCP/IP pour régir ses communications. TCP/IP se répandit par la suite rapidement dans les autres réseaux existants à l'époque (notamment le réseau NSFNET (National Science Foundation Network))
Les réseaux utilisant désormais les mêmes protocoles de communication, ces derniers commencèrent à se regrouper. Sur le sol américain, les réseaux NSFNET et ARPANET fusionnèrent marquant l'apparition du terme Internet, diminutif de "internetwork", rapidement adopté par la communauté internationale pour désigner le regroupement de réseaux informatiques à l'échelle mondiale. Le centre NORSAR (Norwegian Seismic Array), chargé de la détection de tremblements de terre et d'explosions nucléaires, fut le premier nud non américain à rejoindre ce nouveau grand réseau. L'Europe tout entière puis les autres continents intégrèrent par la suite le réseau Internet.
II-B-4. Le World Wide Web▲
A la fin des années 80, Internet était encore un environnement très austère réservé à un public averti. Pour accéder aux ressources présentes sur le réseau, il était nécessaire d'utiliser un terminal et des lignes de commande ce qui constituait un processus laborieux et complexe pour une personne non-initié à l'informatique. Le World Wide Web, tel qu'on le connait a vu le jour, en 1989 au CERN, laboratoire spécialisé dans la recherche nucléaire connu pour être le plus grand centre de recherche en physique des particules au monde (notamment grâce au LHC, un puissant collisionneur de hadrons). Tim Berners-Lee (1955- ), alors informaticien au CERN, proposa à ses supérieurs de créer un système hypertexte permettant aux chercheurs du laboratoire de partager des informations et des documents. Ce système se voulait comme étant la réunion d'un système hypertexte et du réseau Internet, récemment connecté au CERN. Rapidement rejoint (1990) par l'ingénieur belge Robert Cailliau (1947- ), l'idée du World Wide Web fut étoffée et le premier serveur et la première page Web virent rapidement le jour.

Les deux hommes créèrent trois éléments primordiaux pour le Web :
- Le concept d'URL (Uniform Resource Locator) créé pour indiquer l'emplacement d'une ressource sur le Web. Ce concept a été défini dans la RFC 1738RFC 1738 puis mis à jour dans la RFC 3986RFC 3986.
- Le protocole HTTP (HyperText Transfer Protocol) utilisé pour le transfert de données entre des clients et un serveur Web. Ce protocole est décrit dans la RFC 1945RFC 1945 , la RFC 2068RFC 2068 et la RFC 2616RFC 2616.
- Le langage HTML (HyperText Markup Language), inspiré du langage SGML (Standard Generalized Markup Language), permettant de créer des documents hypertextuels (contenant des liens vers d'autres documents).
Le 26 février 1991, ces trois technologies furent présentées par l'équipe de Tim Berners-Lee à l'aide du premier navigateur Web nommé WorldWideWeb.
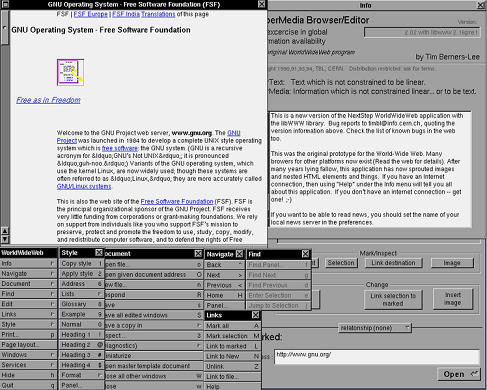
En 1993, le trafic généré par le World Wide Web représentait alors 1% du trafic du réseau Internet. S'appuyant sur les travaux de l'équipe du CERN, le National Center for Supercomputing Applications de l'université de l'Illinois sortit, le 22 avril 1993, un navigateur Web nommé Mosaic conçu pour le système X Windows. Grâce à des nouveautés comme le support des images et des formulaires à l'intérieur de pages Web et à sa simplicité d'utilisation, le navigateur s'imposa rapidement dans le monde. Aujourd'hui, Mosaic est considéré comme le navigateur ayant permis la démocratisation du World Wide Web. Une partie de l'équipe ayant développé Mosaic participa ensuite au développement du navigateur Netscape, un autre succès auprès du grand public sorti en 1994. Netscape souffrit toutefois par la suite de l'arrivée sur le marché du navigateur Internet Explorer. A cause des déboires rencontrés à cette période, la société développant Netscape décida de passer le navigateur sous licence libre et de créer la fondation Mozilla (qui signifie Mosaic Killer) en 1998...

Le 1er Octobre 1994, désireux de créer une organisation internationale chargée de développer le World Wide Web, Tim Berners-Lee fonda le W3C (World Wide Web Consortium). Le siège de l'organisation, tout d'abord situé au MIT, fut par la suite étendu à l'Europe via l'INRIA (Institut National de Recherche en Informatique et en Automatique) en France puis à l'Asie via l'Université de Keio au Japon. Le rôle principal du W3C est de développer des standards pour le Web en émettant des recommandations qui sont des spécifications pour des protocoles, des langages ou plus généralement, des technologies du Web. En fin d'année 1994, on comptait environ 500 serveurs Web dans le monde...
Dans les années qui suivirent, le Web vit l'apparition de nombreux standards et technologies tels que le langage XML (eXtensible Markup Language), le successeur du langage SGML jugé trop complexe, de nouvelles versions pour le langage HTML (HTML 4 en 1997, XHTML 1 en 2000) ou encore les langages Javascript (1995), PHP (Hypertext Preprocessor, 1995) et CSS (1996)... Dans la même période, de nombreux logiciels pour le Web sont également apparus tels que le serveur HTTP Apache (1995) ou les navigateurs Web Safari (2003) et Firefox 1 (2004). De 1995 à aujourd'hui, le Web a connu une évolution fulgurante. En 1996, le Web comptait 100 000 serveurs et environ 36 millions d'utilisateurs. En 2000, on recensait environ 10 millions de serveurs et un peu plus de 360 millions d'utilisateurs...
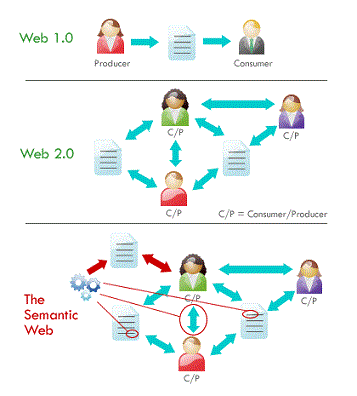
Au delà des technologies, c'est le rôle des utilisateurs du Web vis à vis de son contenu qui à changer au cours des années. D'une manière simplifiée et approximative (et non consensuelle), on distingue trois versions pour le Web qui se sont succédées depuis les débuts en 1990 :
- Le Web 1.0 entre les années 1990 et 2000 où l'utilisateur était avant tout un consommateur d'information. Cette première version du Web est dite "statique" car majoritairement composée de sites où l'information est figée.
- Le Web 2.0 entre les années 2000 et 2010 où l'utilisateur est devenu un acteur actif du réseau. Cette version participative et interactive du Web est dite "dynamique". L'utilisateur est producteur d'informations et participe activement au développement du contenu du Web. Le Web 2.0 est marqué par l'avènement de sites Web tels que Facebook, Twitter et plus généralement des forums de discussions, des blogs ou encore des sites d'E-commerce.
- Le Web 3.0 depuis les années 2010 où les machines deviennent des acteurs à part entière du réseau. Ce web dit "sémantique" voit l'arrivée de technologies permettant aux systèmes informatiques de traiter de manière intelligente les informations circulant sur le Web. Ce fait permet notamment aux ordinateurs de produire de l'information (via des processus de raisonnements automatiques) ou d'adapter le contenu proposé à l'utilisateur en fonction du profil de ce dernier.
Bien qu'une majorité de sites Web soient aujourd'hui dans une "logique 2.0", une transition est entrain de s'opérer vers un Web plus intelligent. Dans la partie suivante de ce cours, nous étudierons les limites du Web actuel qui ont motivé cet effort de transition vers le Web sémantique.
II-C. Limites du Web actuel▲
Nous avons vu dans l'historique précédente qu'Internet s'est développé très rapidement ces dernières années. Le succès du Web a fait qu'il contient aujourd'hui une quantité immense de documents liés entre eux. Pour illustrer l'immensité du Web, [ref](http://www.worldwidewebsize.com/) propose des statistiques sur le nombre de documents indexés par les moteurs de recherche les plus célèbres (en l'occurence Google, Yahoo et Bing). Le 15 mars 2013, le site indiquait que plus de 50 milliards de documents étaient indexés. Bien que cette quantité de document soit déjà très importante, il ne s'agit que de la partie visible (indexée) du Web. En effet, on distingue le Web dit de surface (ou "surface Web") du Web dit profond ou invisible (ou"deep Web"). Ce dernier contient l'ensemble des documents qui sont accessibles mais non indexées par les outils de recherches. En 2001, on estimait que le Web profond était entre 400 et 550 fois plus grand que le Web de surface ce qui représentait une taille de 7500 teraoctets de données à l'époque [ref](http://quod.lib.umich.edu/cgi/t/text/text-idx?c=jep;view=text;rgn=main;idno=3336451.0007.104). Cela représente environ la capacité de 1 600 000 DVD (4.7Go).
De plus, la croissance du Web s'accèlère même car il est aujourd'hui plus facile de produire du contenu à l'aide de services comme Youtube, Facebook, Flickr ou les boîtes e-mails. De plus, l'accès à tous ces services est désormais possibles à tout heure de la journée et à n'importe quel endroit grâce aux technologies mobiles en plein essor. Ainsi d'après [ref](http://www.domo.com/blog/2012/06/how-much-data-is-created-every-minute/), c'est plus de 200 millions d'e-mails qui sont envoyés chaque minute dans le monde, 48 heures de vidéos sur Youtube qui sont uploadées, plus de 550 sites internets qui sont créés ou encore plus de 650 000 contenus qui sont partagés sur Facebook.
Les caractéristiques du Web (sa taille notamment) et la manière dont sont représentées les informations dans le Web posent plusieurs problèmes/questions :
- Comment trouver une information pertinente pour un problème?
- Comment extraire cette information?
- Combiner combiner des informations pour répondre à un problème?
Les difficultés rencontrées par les moteurs de recherche sont une bonne illustration de ces trois limites.
Tout d'abord, les moteurs de recherches sont actuellement (à quelques exceptions près) basés sur des recherches à base de mots clefs.
Ainsi, le sens de la requête n'est pas compris par les moteurs.
La précision (nombre de documents pertinents trouvés par rapport au nombre de documents retournés à l'utilisateur)
et le rappel (nombre de documents pertinents trouvés par rapport au nombre de documents pertinents existants (indexés par le moteur de recherche))
des moteurs de recherche pâtissent de cette limitation.
Exemple 1 : Synonyme Les moteurs de recherche se basant sur la syntaxe et non la sémantique, ils sont très sensibles au termes utilisés
dans la requête ==> renvoie des résultats très différents même si le sens des mots utilisé est proche.
 Automobile en haut, voiture en bas. Résultats différents.
Exemple 2 : Un autre exemple est celui de l'utilisation d'homonymes dans une requête
Automobile en haut, voiture en bas. Résultats différents.
Exemple 2 : Un autre exemple est celui de l'utilisation d'homonymes dans une requête
 Requête avec les termes "François 1er"
Précision moyenne car on a des images du roi François 1er, du pape nouvellement élu, de François Hollande (pour lequel le
lien avec la requête est moins flagrant que pour les deux premiers)
Ces deux exemples illustrent les problèmes liés à la recherche d'informations pertinentes pour rechercher une information.
Requête avec les termes "François 1er"
Précision moyenne car on a des images du roi François 1er, du pape nouvellement élu, de François Hollande (pour lequel le
lien avec la requête est moins flagrant que pour les deux premiers)
Ces deux exemples illustrent les problèmes liés à la recherche d'informations pertinentes pour rechercher une information.
Une fois ces résultats trouvés, l'utilisateur doit encore extraire la réponse souhaitée dans les pages Web retournées par le moteur de recherche.
Ensuite, Les résultats sont des pages Web, il revient ensuite à l'utilisateur de trouver la réponse souhaitée dans la page.
Les moteurs de recherches répondent donc partiellement à l'utilisateur.
Recherche du meilleur buteur de l'équipe de Hockey sur glace des Washington Capitals pour la saison courante
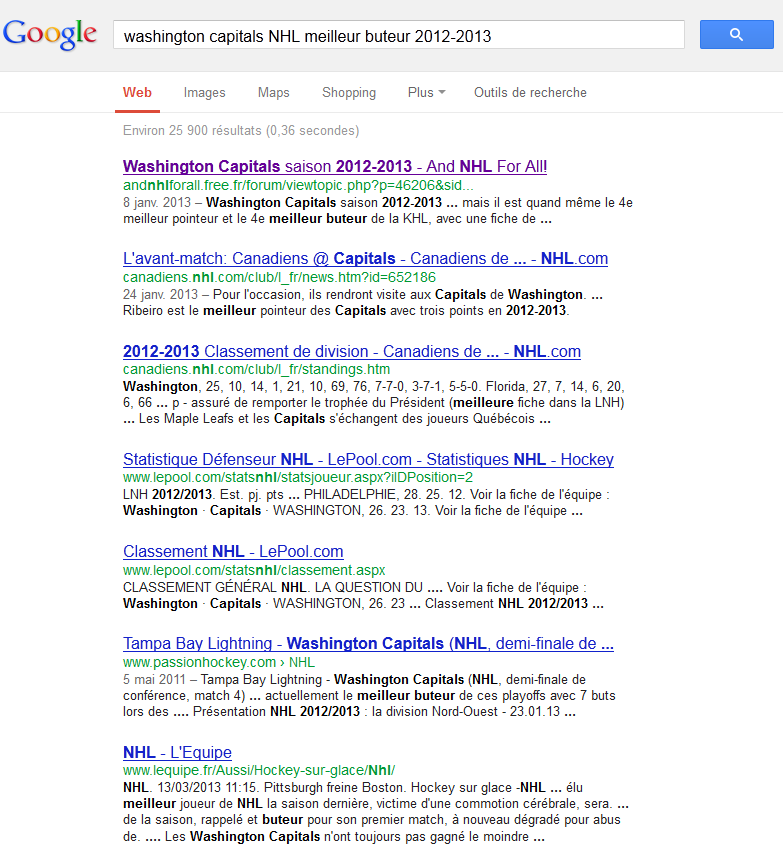 Le moteur de recherche retourne des liens ainsi que des résumés avec lesquels je ne peux répondre à ma question.
Parmi ces liens, visite du site officiel de l'équipe :
Le moteur de recherche retourne des liens ainsi que des résumés avec lesquels je ne peux répondre à ma question.
Parmi ces liens, visite du site officiel de l'équipe :
 Il est maintenant nécessaire de trouver l'information dans le site.
Ce dernier étant en anglais, la recherche n'est pas facilitée.
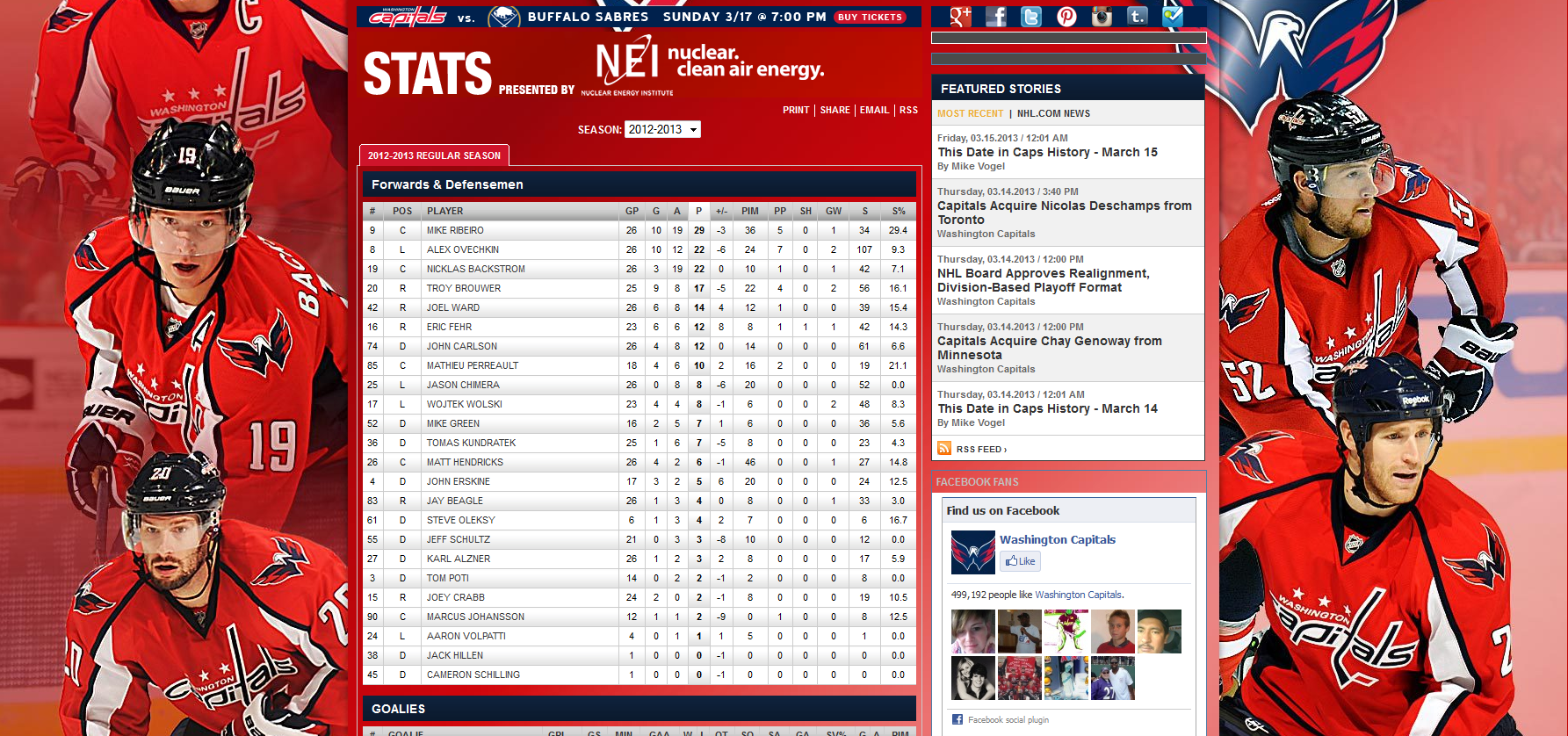
Après quelques tentatives hasardeuses, j'accède finalement à l'information recherchée :
Il est maintenant nécessaire de trouver l'information dans le site.
Ce dernier étant en anglais, la recherche n'est pas facilitée.
Après quelques tentatives hasardeuses, j'accède finalement à l'information recherchée :
Enfin, certaines recherches nécessitent plusieurs requêtes et c'est autant de pages Web résultantes que l'utilisateur doit aggréger pour construire la réponse souhaitée. Exemple de Recherche : Retour en France depuis Dublin (Heure des vols, heure des trains...) Autre exemple Ces limites posent un certain nombre de questions sous-jacentes Cette problématique pose un certain nombre de questions. Tout d'abord, comment évaluer la pertinence d'une information? Quelles sont les informations réellement importantes dans une page Web? Qu'est ce que signifie les informations dans les pages? Pour trouver une information (et par extension, répondre à l'ensemble de ces questions), l'être humain a recours à ses capacités intellectuelles couplées avec trois types de connaissances acquises au long de sa vie : contextual knowledge, world knowledge, experience. La question est de savoir comment peut on faire avec une machine? Le sens est le chaînon manquant. Le web actuel est un vecteur qui se contente de délivrer l'information à l'utilisateur. Le machines du réseau se cantonnent à livrer et afficher les informations pour l'utilisateur. Il revient ensuite à ce dernier d'effectuer le travail d'intérprétation nécessaire pour comprendre ces infos. Les machines effectuent donc des traitements sur la forme des informations et pas sur le fond, inacessible aux machines car celle ci n'ont pas de faculté d'intérprétation. Par exemple, le langage HTML permet de spécifier comment l'information est présentée et comment les documents sont reliés entre eux. Mais HTML ne permet pas de spécifier le sens des informations. Les solutions pour proposer un Web plus évolué est de donner les moyens aux machines de lier automatiquement des données (pour éviter à l'utilisateur de devoir aggréger les informations résultantes d'une recherche) Augmenter la précision et le recall des recherches Donner aux machines des capacités de raisonnement leur permettant de se substituer en partie aux utilisateurs pour des tâches consommatrices de temps. Transition vers la partie suivante : Toutes ces solutions passent par une seule chose : la création de moyens technologiques permettant de spécifier le sens (la sémantique) des informations de manière explicite et formel (afin qu'elle puisse être traité par les machines) On a en effet vu que le problème majeur aujourd'hui était que les machines ne comprennent pas le sens des données. Permettre aux machines de saisir le sens des informations du Web, c'est leur donner la possibilité d'effectuer des traitements plus intelligents et efficaces et de mieux satisfaire les besoins de l'utilisateur. Dans la partie suivante, j'introduirai le Web sémantique, une extension du Web actuel qui permet justement de combler le fossé entre les machines et le sens des informations. http://en.wikipedia.org/wiki/Semantic_Web#Limitations_of_HTML
II-D. Vers un Web plus intelligent...▲
II-D-2. Vue d'ensemble▲
Définition "Le Web sémantique est une extension du Web actuel dans lequel la signification de l'information est clairement définie afin de permettre aux ordinateurs et aux personnes de coopérer plus efficacement" Tim Berners-Lee, James Hendler, Ora Lassila The Semantic Web, Scientific american, May 2001 Historique Voir Papini cours 1 4 Principes des données liées 5 étoiles de l'open Data (Tim Berners Lee)
II-D-3. Architecture▲
II-E. Conclusion▲
II-F. Bibliographie▲
Histoire d'Internet http://en.wikipedia.org/wiki/History_of_the_Internet http://www.internetsociety.org/internet/what-internet/history-internet/brief-history-internet http://www.computerhistory.org/internet_history/ http://www.zakon.org/robert/internet/timeline/ http://www.linternaute.com/histoire/categorie/138/a/1/1/histoire_d_internet.shtml Système Memex http://fr.wikipedia.org/wiki/Memex Vannevar Bush http://fr.wikipedia.org/wiki/Vannevar_Bush Hypertexte http://people.lis.illinois.edu/~wrayward/otlet/xanadu.htm https://en.wikipedia.org/wiki/Hypertext http://en.wikipedia.org/wiki/NLS_%28computer_system%29 https://en.wikipedia.org/wiki/Hypertext_Editing_System Année géophysique internationale http://fr.wikipedia.org/wiki/Ann%C3%A9e_g%C3%A9ophysique_internationale DARPA http://en.wikipedia.org/wiki/DARPA
III. Représentation de faits▲
III-A. Identification des objets▲
Triangle sémiotique : Symbole, référence et référent URI Objectifs URL et URN Syntaxe Exemples d'URI
III-B. Représentation de faits simples▲
III-B-1. XML▲
Objectifs Structure d'un document XML et syntaxe Racine Element Attributs Commentaires Namespace Introduction d'un exemple de fichier XML qui sera par la suite traduit en RDF
III-B-2. RDF▲
Objectifs Triplet : Ressource (URI), prédicat (URI), objet (URI/Littéral) Représentation graphique triplet Littéral, XML Schema datatypes, tags langages Graphe RDF Représentation graphique Noeuds vides Listes Conteneur : Bag, Seq et Alt Collection Réification Statement Formalismes RDF-XML N3 Turtle Application avec Jena, construction de modèle simple
III-C. Représentation avancée de faits▲
RDFS Objectifs Description des éléments du langage Inférence Application avec Jena, construction d'une base de connaissances RDF complète Limites de RDF/RDFS
IV. Manipulation de faits▲
IV-A. Interrogation et manipulation d'une base de connaissances RDF▲
IV-A-1. SPARQL▲
Variables Patron de graphes Requête SPARQL SELECT SELECT, FROM, WHERE PREFIX et BASE ORDER, LIMIT, OFFSET FILTER, OPTIONAL, UNION ASK, CONSTRUCT, DESCRIBE Application avec Endpoint DBPedia
IV-A-2. SPARQL avancé▲
Requête SPARQL SELECT Assignements : BIND Fonctions d'aggrégation : COUNT, SUM, AVG Requêtes imbriquées Négation : EXISTS, NOT EXISTS, MINUS Chemins de propriétés Requête SPARQL UPDATE Application avec Endpoint DBPedia
IV-B. Stockage de connaissances▲
Triple store Application avec Jena TDB
IV-C. Création de données sémantiques pour le Web▲
Microformats RDFa Microdata
V. Représentation de connaissances et ontologies en théorie▲
V-A. Ontologie▲
V-B. Logique propositionelle▲
V-C. Logique du premier ordre▲
V-D. Représentation formelle de connaissances▲
Logique de description Application avec Racer